
大家好,我是小智,最近 Deepseek 真是持续火出圈,很多万年跟 AI 打不上联系的朋友同事陆陆续续跑来问我
就现在 Deepseek官网这么个卡卡状态,到底啥时候结束,有什么替代方案不,还有市面上那么多的 Deepseek,为啥有的用起来感觉更像是大聪明,有的取代自己不远的感觉了呢?
其实这些都不是大家的错觉,虽说都叫 Deepseek,但是模型的参数还是有大有小的。
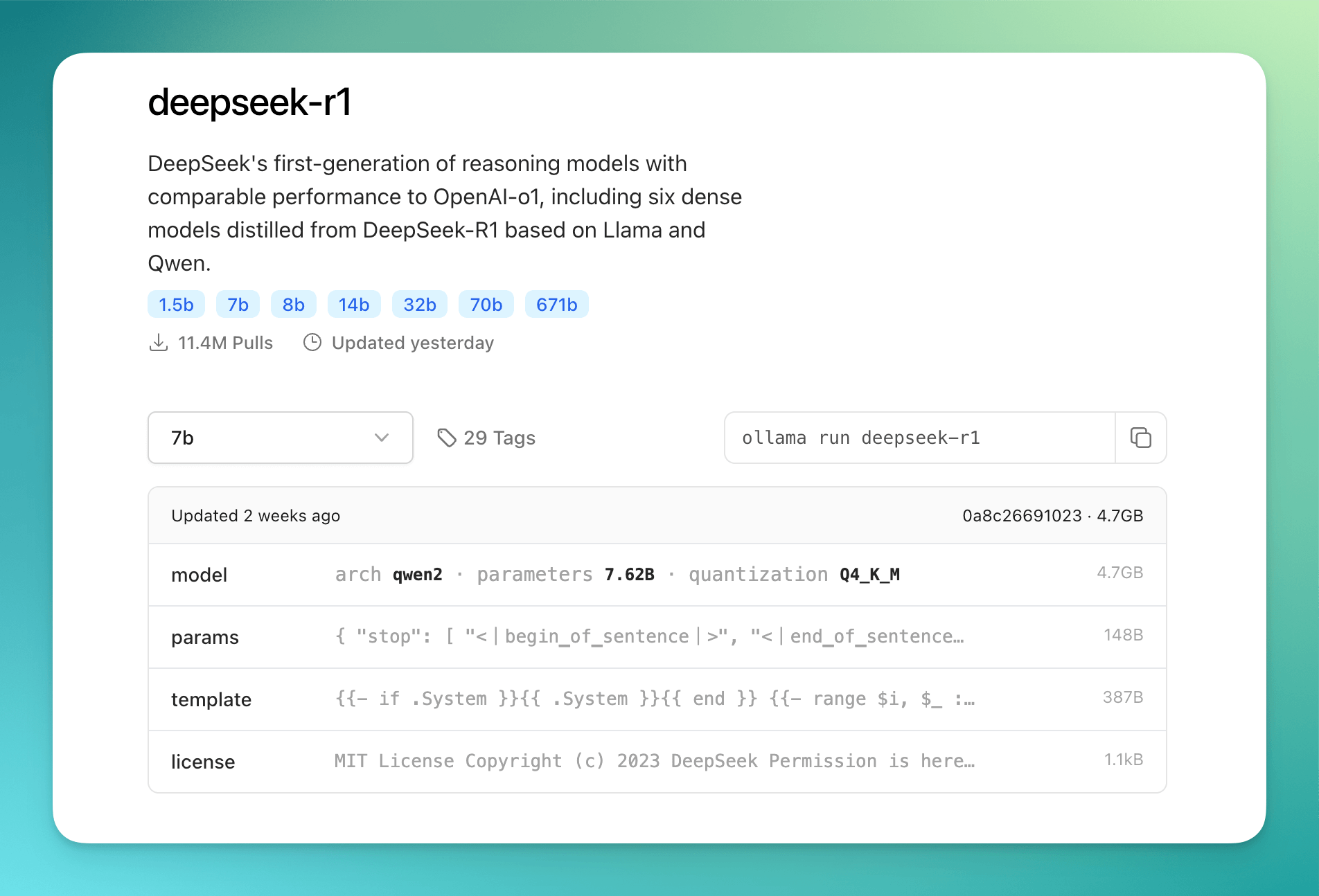
就以这次开源的 Deepseek-R1 模型为例,ollama 总共给了1.5b、7b、8b、14b、32b、70b、671b这么些个参数。
而Deepseek 官网用的,正是满血的 671b 版本。
你可以想象小模型是速食汤,而大模型是上海米其林大厨精心熬炼一整天的浓汤,那喝起来,当然不可能一样。

一般而言,参数数量越多,模型的复杂度和潜在能力也越强,但同时对计算资源的需求也更高。
以 RTX 4060 显卡为例,家用计算机一般可以运行 DeepSeek 的 8B 左右的参数模型。
所以若无特殊需求,还是推荐大家使用官方搭建好的服务。
下面小智就亲自给大家测试看看,从 1.5b 模型到 671b 模型,究竟有多大的差距。
下方都是我自己在 Mac 上面部署的 Deepseek 模型,由于财力所限,最高只能跑到 70b。

首先是 1.5b 模型,可以看出模型虽小,但是结构化的输出还是非常明显的。

7b-32b 模型,其实看不出太多的不同之处,都是罗列了一些比较“正确的废话”,甚至 7b 的模型输出还有一些中英夹杂的错误。
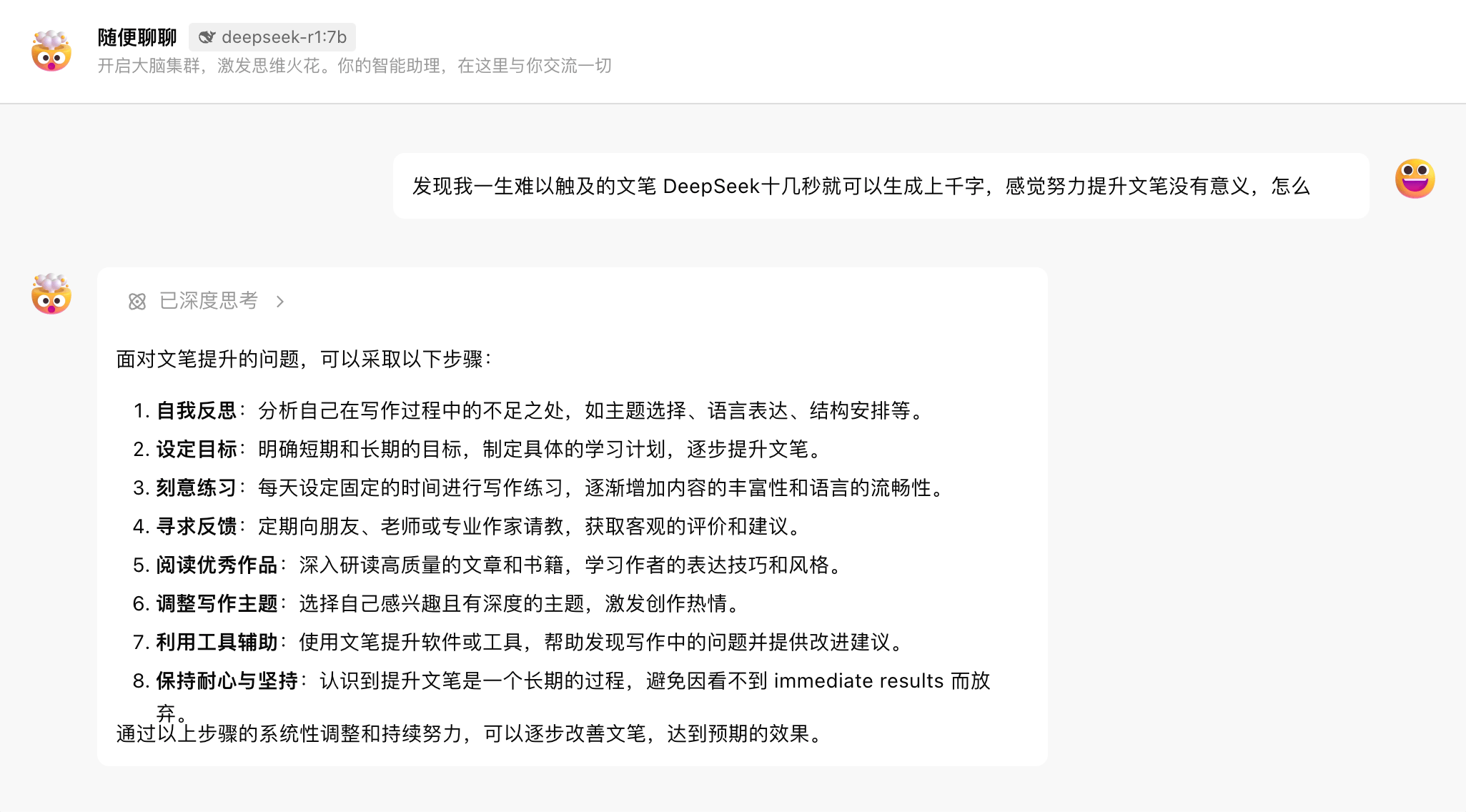
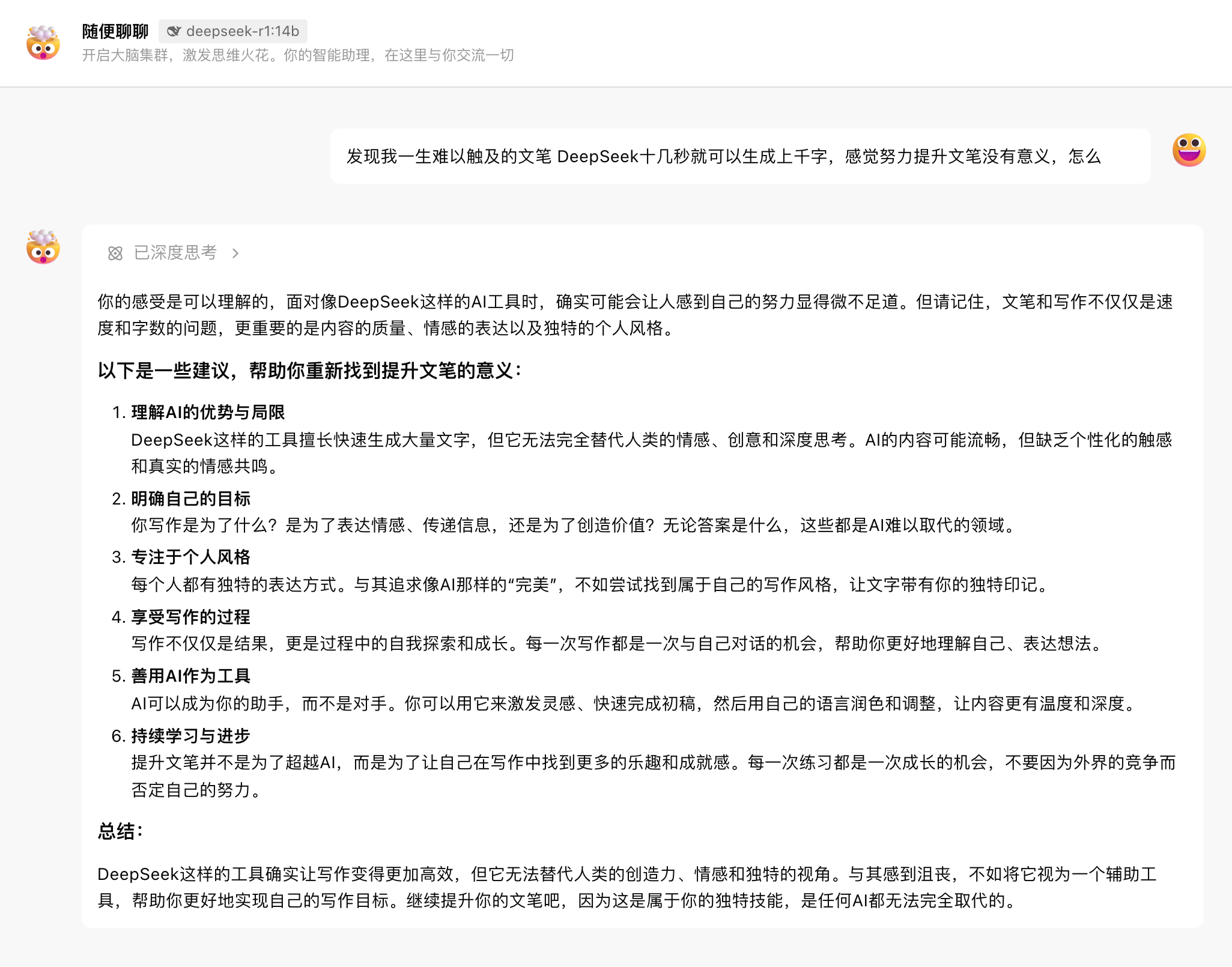

甚至可以说,这次 70b 的模型,表现也仅仅只能用平平来概括。
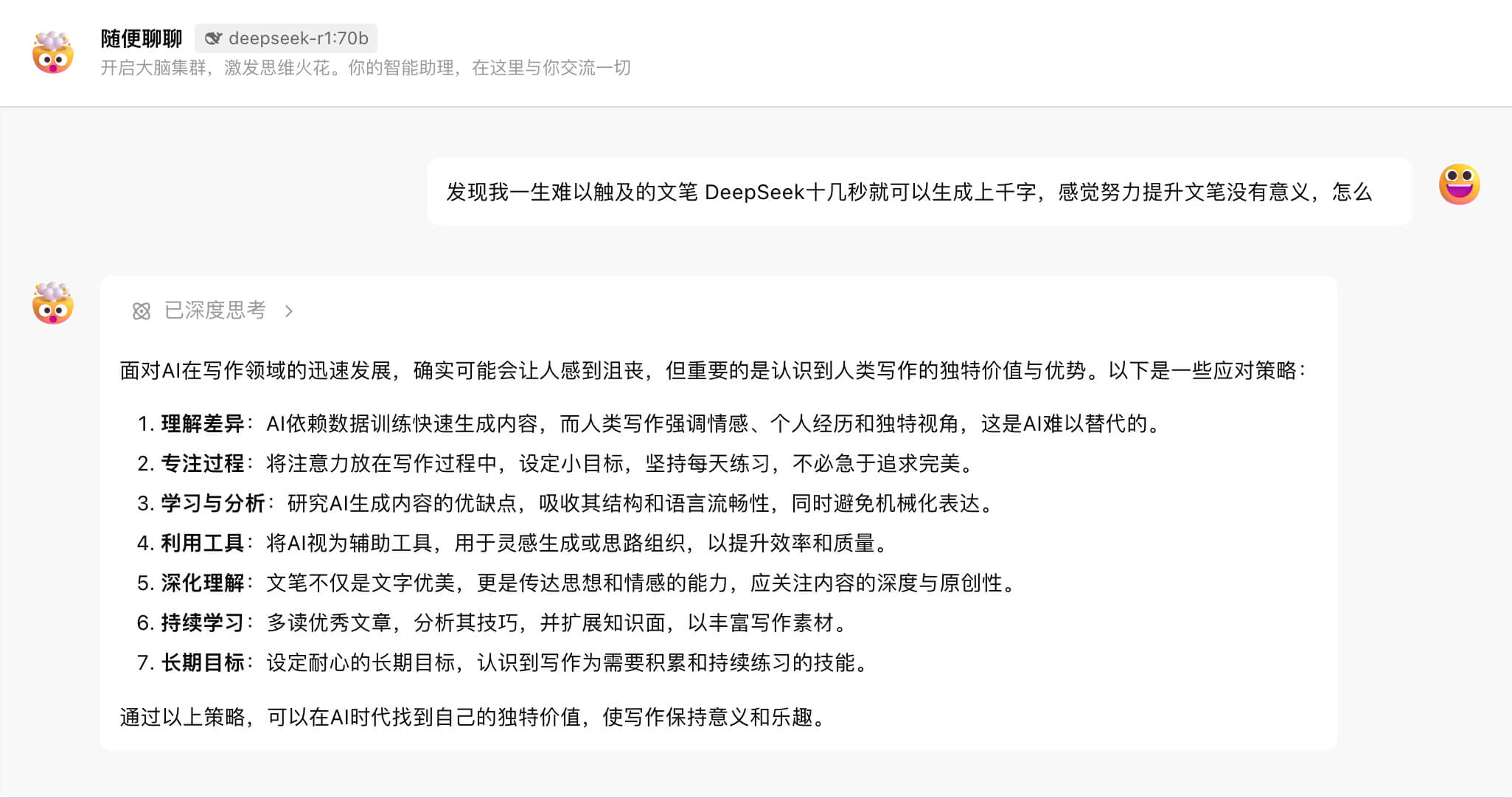
重头戏来了,让我们看看满血版 671b 的表现吧
内容有些太长,感兴趣的朋友可以自己滑动翻阅,这里小智把一些关键的句子摘给大家瞧瞧
人类文明史上,甲骨卜者不会因毛笔问世放弃刻写,书记官也不会因印刷术普及而停止誊抄。20世纪80年代美国诗人曾集体抵制word处理器,担心“撤销键会扼杀诗歌的神圣性”,但最终催生出更多实验性文本创作。AI生成工具正在重演这一历史进程, 但诗歌仍在生长。
掘暗知识尝试描写”母亲切土豆时手腕的弧度”,AI能生成流畅比喻,但无法捕捉您五岁时仰望的那个特定黄昏。
当您坚持用手工打字机敲出第一个病句时,早已在数字洪流中留下了反抗熵增的生命印记。那些在深夜里删除又重写的段落褶皱,终将成为AI无法解析的文明地形图。建议保留所有创作草稿,百年后的人类学家将在这些修改痕迹里,发现智能时代最动人的人性光芒。
(本思考过程耗费1024个token,用时12.8秒,这或许正是我们需要人类的理由——有些思考,本就不该被量化)

是啊,这或许正是需要人类的理由——有些思考,本就不该被量化。
评论列表 (0条):
加载更多评论 Loading...